前向渲染与延迟渲染
如果您开发过3D游戏,那么您可能会在现代图形引擎的研究中遇到术语“前向渲染”和“延迟渲染”。
而且,通常,您必须选择一种在游戏中使用。但是它们是什么,它们有什么不同,应该选择哪一个?

许多灯光的延迟渲染
现代图形管道
首先,我们需要对现代的或可编程的图形管线有所了解。
过去,我们在显示卡图形处理方面所受的限制。除了发送不同的纹理外,我们无法更改其绘制每个像素的方式,并且一旦顶点在卡上就无法扭曲顶点。但是时代变了,我们现在有了可编程的图形管线。现在,我们可以将代码发送到显卡,以更改像素的外观,使它们具有法线贴图的凹凸外观,并增加反射效果(以及极大的真实感)。
该代码采用geometry,vertex和fragment shader的形式,它们实质上改变了显卡渲染对象的方式。
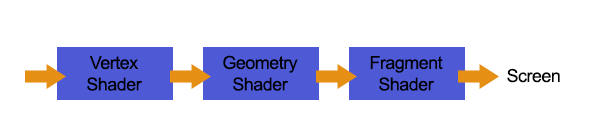
可编程图形管线的简化视图
前向渲染
前向渲染是大多数引擎使用的标准,即用型渲染技术。您为图形卡提供几何图形,将其投影并将其分解为顶点,然后将其转换并拆分为片段或像素,这些片段或像素将在传递到屏幕之前进行最终的渲染处理。
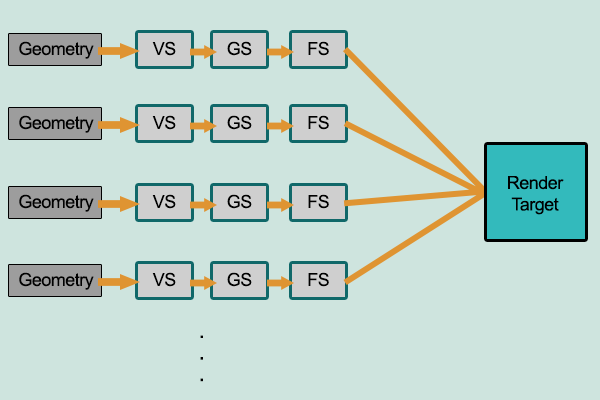
前向渲染:几何着色器到顶点着色器到片段着色器
它是相当线性的,并且每次将每个几何图形向下通过管道一次以生成最终图像。
延迟渲染
顾名思义,在延迟渲染中,渲染将延迟一点,直到所有几何图形都通过管道为止。然后通过在最后应用阴影来生成最终图像。
现在,我们为什么要这样做?
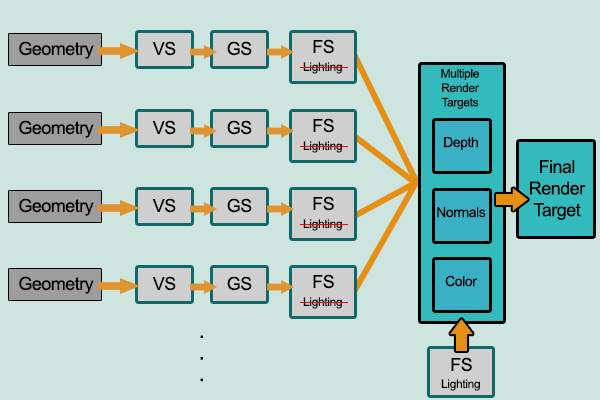
延迟渲染:顶点到片段着色器的几何形状。传递到多个渲染目标,然后使用照明进行着色。
延迟照明是对延迟渲染的一种修改,它通过在场景中使用更多遍来减小G缓冲区的大小。
照明性能
照明是走一条路线而不走另一条路线的主要原因。在标准的前向渲染管线中,必须对可见场景中的每个顶点和可见场景中的每个片段执行照明计算。
如果您的场景具有100个几何图形,并且每个几何图形都有1,000个顶点,那么您可能有大约100,000个多边形(非常粗略的估计)。显卡可以很轻松地处理此问题。但是,当这些多边形被发送到片段着色器时,就会在此处进行昂贵的照明计算,并可能发生真正的减速。
开发人员尝试将尽可能多的光照计算推入顶点着色器,以减少片段着色器必须完成的工作量。
必须为屏幕上每个多边形的每个可见片段执行昂贵的照明计算,无论其是否重叠或被另一个多边形的片段隐藏。如果屏幕的分辨率为1024x768(绝对不是很高的分辨率),则需要渲染近800,000像素。您每帧可以轻松完成一百万个片段操作。而且,许多碎片永远不会进入屏幕,因为它们经过深度测试已被移除,因此照明计算被浪费了。
如果您有一百万个这样的片段,并且突然间您必须为每个灯光重新渲染该场景,那么您就跳到了[num lights] x 1,000,000每帧的片段操作!想象一下,如果您有一个充满路灯的城镇,而每个镇都是一个点光源…
可以使用大O表示法来编写用于估算此前向渲染复杂度的公式,如O(num_geometry_fragments * num_lights)。您可以在此处看到复杂度与几何图形数量和灯光数量直接相关。
碎片是可能的像素,如果深度测试未将其剔除,它们将最终出现在屏幕上。
现在,一些引擎通过切掉远处的灯光,组合灯光或使用光照贴图(非常流行,但静态)来优化此效果。但是,如果您需要动态光源以及很多动态光源,我们需要一个更好的解决方案。
延迟渲染以进行救援
延迟渲染是一种非常有趣的方法,它减少了对象数量,特别是减少了总片段数,并在屏幕上的像素上执行了照明计算,从而使用分辨率大小代替了总片段数。
大O标记表示的延迟渲染的复杂度为:O(screen_resolution * num_lights)。
您可以看到,现在屏幕上确定有多少个对象都无关紧要,因此您可以愉快地增加照明数量。(这并不意味着您可以拥有无限的对象,它们仍然必须绘制到缓冲区以产生最终的渲染结果。)
让我们看看它是如何工作的。
大心脏的延迟渲染
使用多个渲染目标,将每个几何图形(但不带阴影)渲染到多个屏幕空间缓冲区。特别是,深度,法线和颜色都写入了单独的缓冲区(图像)。然后将这些缓冲区组合起来,以为每个光提供足够的信息以照亮像素。

Color,Depth和Normal缓冲区。

使用三个缓冲区生成的最终照明(阴影)结果。
通过知道像素有多远及其法线向量,我们可以将像素的颜色与光线结合起来以生成最终的渲染。
如何选择正确的渲染哪个?
简单的说,如果您使用许多动态光源,则应使用延迟渲染。但是,存在一些重大缺点:
- 此过程需要具有多个渲染目标的显卡。旧显卡没有此功能,因此无法使用。
- 它需要更高带宽。G-buff的原因,延迟渲染需要大量缓冲区,旧的显卡可能也无法处理。
- 不能使用透明对象。(可以配合前向渲染结合在一起,解决此问题。)
- 没有抗锯齿。但也有解决方案:边缘检测,FXAA。
- 除非您使用对延迟渲染的修改称为Deferred Lighting,否则仅允许一种类型的材料。
- 阴影仍然取决于灯光的数量,延迟渲染无法解决此问题。
如果您没有很多灯光或者希望能够在较旧的硬件上运行,则应坚持使用前向渲染,并用静态光照贴图替换很多灯光,结果也是很棒的。
结论
我希望此文会帮助你们对前向渲染和延迟渲染有所了解。您可以使用各种选项来解决渲染问题,但是在游戏开发开始时选择正确的选项非常重要,以避免以后出现困难的更改。
另外在U3D中还有顶点光照渲染,其功能完全可以在延迟渲染中实现,所以没有单独拿出来讨论。
前向渲染和延迟渲染的区别
前向渲染和延迟渲染是两种光照渲染模式。
假设有1个光源和1000个具有光照反射的三角形在view coordinate沿着z轴正方形延伸摆放,法线与z轴平行,即所有三角形xy全相同,只有z不同,但是这里增加一个条件:摆放顺序是无序的。
从屏幕上其实你只能看到一个带光照的三角形,其他的都被挡住了。
那么前向渲染会这样做:
- 遍历1000个三角形片元
- 进行深度检测,没通过的忽略
- 通过检测的进行光照计算
- 更新帧缓冲区
- 返回1继续直到遍历结束
由于上面的要求是无序摆放,那么如果运气差一点 1000次深度检测全部都能通过,那么光照会计算1000次,可是因为只能看见最上面的,那么999次光照计算都是多余的。如果光源越多第三步的重复次数越多,整体复杂度也会越高。
延迟渲染引入了GBuffer,它会这样做:
- 遍历1000个三角形片元
- 进行深度检测,没通过的忽略
- 通过的将坐标、光照等信息写入GBuffer
- 返回1继续直到遍历结束
- 遍历Gbuffer
- 利用Gbuffer中的数据进行光照计算
- 更新帧缓冲区
- 返回5继续直到遍历结束
延迟渲染先把可以显示在屏幕上的像素点的相关参数保存下来,然后只进行了一次光照计算就实现了最终效果。这样大大节约了光照计算复杂度。每增加一个光源,只会增加一次整体的光照计算。所以延迟渲染的好处显而易见了。
然而,世间无完美之事,GBuffer只能给屏幕上的每一个点保存一份光照数据,但是如果这些三角形都是半透明的怎么办?
无解–# Blend已废。
由于Gbuffer存的都是像素值,无法体现出每个像素对应的原始模型,那么多重采样抗锯齿功能也无法实现。三角形可能还好点,画圆就悲剧了。
所以如果各位大哥对Blend混合和抗锯齿有要求,那么Gbuffer可能就不太适合了。
本文来自:
https://zhuanlan.zhihu.com/p/111314574
https://gamedevelopment.tutsplus.com/articles/forward-rendering-vs-deferred-rendering--gamedev-12342
https://blog.csdn.net/qq_26900671/article/details/100984838